采集正则写法
帝国cms采集正则写法
本文目录- 帝国CMS的采集正则
帝国CMS的采集正则
1、作用:通过设置采集正则以便使系统识别你要采集的内容。
2、帝国CMS的采集正则是什么样的,下面我们用实例讲解:
(1)、假如我们要采集页面的内容页为如下页面:
图1:HTML页面
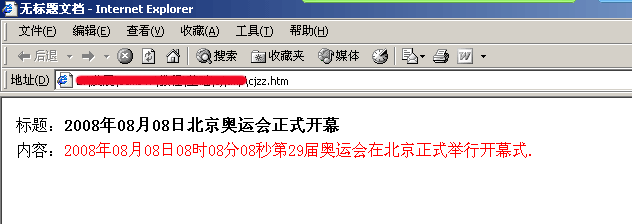
图2:查看页面源代码为如下:
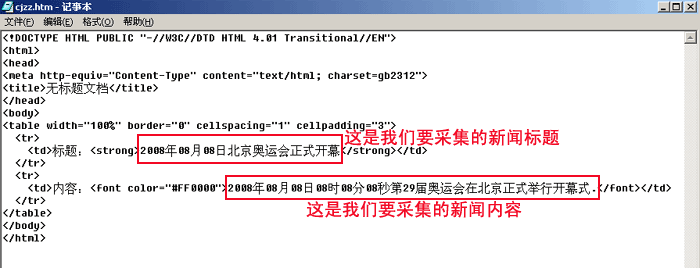
(2)、由上图的源代码内容我们可以得出帝国CMS的采集正则:
新闻标题正则
<td>标题:<strong>[!--title--]</strong></td>
新闻内容正则:
<td>内容:<font color="#FF0000">[!--newstext--]</font></td>
上面中的"[!--title--]"与"[!--newstext--]"分别为"标题"字段与"内容"字段的正则变量。用于指定我们要采集的内容位置。
(3)、由上面我们得出了,帝国CMS采集正则是把正则变量替换要采集内容后的代码内容。格式:
识别代码头部[!--变量名--]识别代码尾部
注意事项:上面的"识别代码头部"一定是要唯一的标记。
3、帝国CMS正则还有表示任意内容的字符:"*"
如果"识别代码头部"中有内容是变化的,那么我们可以用*代替它。如页面源代码为如下,我们要采集下面的链接地址:
<a title="任意可变内容" href="链接地址">标题</a>
通过使用"*"任意内容表示字符,我们可以用下面的正则忽略可变内容,获得链接地址:
<a title="*" href="[!--newsurl--]">
附加说明:[!--newsurl--]为页面链接地址的正则变量。
4、其他说明:
(1)、正则要找出唯一性的开头字符。有时候空格都会成为识别的依据。
(2)、对于特殊字符请在前面加上"",当然直接将特殊字符改为"*"最合适了。特殊字符如下: " )"、"("、"{"、"}"、"["、"]"、""、"?"等等。